確率・統計の基礎¶
本節では機械学習で用いる確率論、統計学の概念や用語を解説します。
世の中には「ランダム」に起こる出来事、もしくは背景のメカニズムがわからないため「ランダム」として扱わざるを得ない出来事が存在します。そのようなランダムな出来事を理論的に扱うには、出来事そのものや、ある出来事と別の出来事の関連を数学的に記述できなければなりません。確率論ではランダムな出来事のことを事象 (event)と呼びます(厳密な定義は本資料では省略します)。
本節では、まず事象を記述する道具として確率分布を導入し、それに関連する概念(周辺確率、条件付き確率、確率変数の独立)を解説します。さらにこれらの概念を用いてベイズの定理を説明します。ベイズの定理により、ある出来事が観測された時に、その原因となる出来事が起こった確率の計算ができるようになります。 次に、確率分布の中から観測データに適合した最適な確率分布を選択する方法である、最尤推定と事後分布最大化推定(MAP 推定)を紹介します。 機械学習の文脈では、これらは訓練モデルの「最適な」パラメータを決定することに対応します。 最後に、機械学習で頻繁に利用される統計学の用語(平均、分散、標準偏差、相関係数など)を解説します。
確率・統計と機械学習の関係¶
機械学習システムが学習に用いるのは限られた数の観測データですが、多くの機械学習タスクでやりたいことは、与えられた観測データの背後にある普遍性や法則を捉え、将来の出来事に対し予測を行えることです。機械学習ではそれを達成するために統計学の考え方を利用します。
統計学では、ある集団すべてについて調査ができない時、集団からランダムサンプリングを行い元の集団の性質を推定します。手元にある観測データが、何らかの法則に従って得られる確率的なサンプルであると考えることで、機械学習と統計学がつながります。 統計学を利用することで、あるデータが未知のデータ源から発生しやすいか、データが外れ値かどうか、どういった方法でモデルを学習させればよいか、といった問題を客観的に判断することができるようになります。また、学習させたモデルの性能に対して理論的な保証を与えることも統計学により可能となります。 このような、機械学習の統計学としての側面を強調する場合、機械学習を特に「統計的機械学習」と呼びます。
確率変数と確率分布¶
現代数学で広く利用されている「確率」の概念を定式化するには様々な準備が必要になるため、この資料では「確率」という言葉を数学的に厳密には定義しません。代わりに次のように考えます。ある対象としている現象の中で、様々な事象があり得るとき、それぞれの事象ごとに、それが「どの程度起きそうか」という度合いを考えます。確率とはその度合いのこととします。そして、その確率に従って、色々な値をとりうる確率変数(random variable)を考えます。確率変数は、名前に「変数」とついていますが、「事象」を「数値」に変換する関数と考えると理解しやすくなります。例えば、「コインを投げて表が出る」という「事象」を、「1」という「数値」に変換し、「コインを投げて裏が出る」という「事象」を、「0」という「数値」に変換する関数を考えると、これは「1」か「0」という値のどちらかをとりうる確率変数だ(注釈1)ということになります。
それでは、確率的現象の具体例を考えてみます。ある歪んだサイコロがあり、「サイコロを投げて \(x\) という目が出た」という事象(注釈2)を、\(x\) という数値に対応させる確率変数 \(X\) があるとします。そして、この確率変数がとりうる全ての値が、それぞれどのような確率で出現するかを表した以下のような表があります。
確率変数 \(X\) の値 |
その値をとる確率 |
|---|---|
1 |
\(0.3\) |
2 |
\(0.1\) |
3 |
\(0.1\) |
4 |
\(0.2\) |
5 |
\(0.1\) |
6 |
\(0.2\) |
このような表を確率分布 (probability distribution) と呼びます。確率分布には重要な制約があり、「確率変数がとりうるあらゆる値の確率をすべて足すと和が必ず \(1\) になること」及び「全ての確率は \(0\) 以上の値であること」の両者を常に満たします。上の表の左の列に並ぶ数値を実現値と呼び、小文字の \(x\) で表します。そして、右の列に並ぶそれぞれの \(x\) に対応する確率を \(p(x)\) と書くことにします。すなわち上の表から \(p(1) = 0.3\) , \(p(2) = 0.1\) , \(\ldots\) です。この表記を用いると、確率分布が持つ2つの制約は、以下のように表せます。
ここで、 \(\sum_x\) は全てのありうる \(x\) の値にわたる和を表し、例えば上のサイコロの例では、 \(\sum_{x=1}^6\) と同じことを意味します。 \(\forall x\) は、あり得る \(x\) の値すべてにおいて、右の条件( \(p(x) \geq 0\) )が成り立つ、ということを意味しています。
\(p(1) = 0.3\) というのは、確率変数 \(X\) が \(1\) という値をとる確率ということですが、これを \(p(X = 1) = 0.3\) とも書きます。前述の \(p(x)\) は、確率変数 \(X\) の存在を暗に仮定し、 \(p(X = x)\) を簡単に表記したもの、すなわち \(X\) という確率変数がある値 \(x\) をとる確率と考えることができます。一方、 \(p(X)\) と確率変数だけを引数にとる場合、これは上の表のような確率分布を意味します。
同時分布・周辺確率¶
前節では、1 つの確率変数について、その分布(確率分布のこと)とは何かと、分布が持つ制約について説明しました。この節では、複数の確率変数が登場する場合について考えます。
まず具体例を用いて考えてみます。ここに 2 つのサイコロがあり、それぞれのサイコロの出目を 2 つの確率変数 \(X, Y\) で表します。この 2 つのサイコロを同時に振って、1 つ目のサイコロが \(x\) という値をとり、2 つ目のサイコロが \(y\) という値をとったという事象の確率は、以下のように書き表します。
\(x, y\) はいずれも \(1, 2, 3, 4, 5, 6\) の6つの数字のどれかです。例えば、「3」と「5」の目が出る、という事象が起こる確率は
と表されます。このように、 \(X = 3\) となるかつ \(Y = 5\) となる、といった複数の条件を指定したときに、それらが全て同時に成り立つ確率のことを、同時確率(joint probability)と呼びます。
では次に、この 2 つのサイコロを別々に見てみましょう。例えば、「1 つ目のサイコロが \(3\) の目を出した」という事象が起こる確率 \(p(X = 3)\) は、1つ目のサイコロが \(3\) かつ 2 つ目のサイコロが \(1\) のとき/ \(2\) のとき/ \(3\) のとき/…/ \(6\) のとき、の6つのパターンが発生する確率を全て足したものになります。つまり、
と書けます。このとき、 \(\sum_y\) は「 \(Y\) のとり得るあらゆる値 \(y\) についての和」という意味です。これを、「(2 つ目のサイコロの目がなんであれ) 1 つ目のサイコロの目が \(x\) である確率」と一般化すると、以下のようになります。
同様に、「(1つ目のサイコロの目がなんであれ)2 つ目のサイコロの目が \(y\) である確率」は、1つ目のサイコロについてあり得る値すべての確率の和を取れば良いので、
となります。このように、同時確率が与えられたとき、着目していない方の確率変数がとり得る全ての値について同時確率を計算しその和をとることを周辺化 (marginalization) と呼び、結果として得られる確率を周辺確率 (marginal probability) と呼びます。 また、周辺確率をその着目している確率変数がとり得る全ての値について並べて一覧にしたものが周辺確率分布 (marginal probability distribution) です。 さらに、上の例のように2つの確率変数の同時確率を考えるとき、とり得る全ての組み合わせの確率を一覧にしたものが、同時分布 (joint distribution) です。
ここで、2 つのサイコロの同時分布の表は大きくなってしまうので、より簡単な例として、表が出る確率と裏が出る確率が異なる 2 つのコインを考えてみましょう。この 2 つのコインを同時に投げたときの表裏の組み合わせについての同時分布が、以下のようになったとします。
\(\ \) |
Y = 表 |
Y = 裏 |
|---|---|---|
X = 表 |
1 / 5 |
2 / 5 |
X = 裏 |
1 / 5 |
1 / 5 |
ここで、1 つ目のコインの表裏を表す確率変数を \(X\) 、2 つ目のコインの表裏を表す確率変数を \(Y\) としています。表の中身がどういう意味を持っているか確認してください。2 つのコインが両方表になる確率は \(p(X = 表, Y = 表) = 1 / 5\) となっています。他のマスに書かれている同時確率の値の意味も確認してください。
では、この表の中の数字を、行ごとに合計してみましょう。1 行目は、
です。 これは、 \(\sum_y p(X = 表, Y = y)\) (注釈3)を計算していることになるので、周辺化によって \(p(X = 表)\) という周辺確率を求めていることに相当します。
同様に、1 列目の値を合計してみると、今度は \(\sum_x p(X = x, Y = 表)\) (注釈4) を計算することに相当し、これは周辺化によって \(P(Y = 表)\) という周辺確率を計算していることになります。
こうして計算される周辺確率を、上の同時分布の表に書き入れてみます。
\(\ \) |
Y = 表 |
Y = 裏 |
p(X) |
|---|---|---|---|
X = 表 |
1 / 5 |
2 / 5 |
3 / 5 |
X = 裏 |
1 / 5 |
1 / 5 |
2 / 5 |
p(Y) |
2 / 5 |
3 / 5 |
このように、周辺確率はしばしば同時分布表の周辺に記述されます。
条件付き確率¶
前節では、複数の確率変数を同時に考える方法として、同時確率および同時分布という概念と、同時確率と一つ一つの確率変数のみに着目した際の確率(周辺確率)の間の関係を、周辺化という計算で説明しました。 本節では、「とある条件下での着目事象の確率」を考える条件付き確率 (conditional probability) という概念を説明します。 これまでの節で扱っていた確率では、まず対象とする現象について、考えうる全ての事象を考え、そのうち対象とする事象が起きる確率はいくらか、を考えていました。 一方、条件付き確率は、それらの考えうる事象のうち、特定の条件を満たした事象のみをまず抜き出し、その中で、さらに着目する特定の事象が起きる確率を考えるためのものです。
例えば、あるお店にやってきた人(以下、客)が傘を持っているときに \(1\) 、持っていなかったときに \(0\) をとる確率変数 \(X\) を考えます。 また、ある客がやってきたときに外で雨が降っていたときに \(1\) 、降っていなかったときに \(0\) をとる確率変数 \(Y\) を考えます。 客が傘を持っていたかと、その瞬間に雨が降っていたかどうか、という 2 つの情報が組となったデータが 16 個あるとします。 16 人の客を観測してデータを集めた、ということです。 それは以下の様なものでした。
傘 ( \(X\) ) |
雨 ( \(Y\) ) |
|---|---|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
これらのデータから、確率変数 \(X, Y\) の同時分布表を作成すると、以下のようになります。この表の作り方は、例えば表の左上のマスは \(X = 0\) かつ \(Y = 0\) となっているデータが 16 個中何個あるかを数えて、その割合を記入すればよく、他のマスについても同様となります。
\(\ \) |
Y = 0 |
Y = 1 |
|---|---|---|
X = 0 |
6 / 16 |
3 / 16 |
X = 1 |
1 / 16 |
6 / 16 |
では、「客が傘を持っていた( \(X = 1\) )」という条件の下で、「そのとき雨が降っていなかった( \(Y = 0\) )」という確率は、どのようになるでしょうか?
まず、「客が傘を持っていた( \(X = 1\) )」という状況下のデータだけを、上の同時分布表から抜き出してきましょう。
傘 (\(X\)) |
雨 (\(Y\)) |
|---|---|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
全部で 7 個のデータがあり、この中で「雨が降っていなかった( \(Y = 0\) )」となっているデータは 1 個です。すなわち、「客が傘を持っていたという条件の下で、そのとき雨が降っていなかった確率」は \(1 / 7\) となります。これを、以下のように書きます。
これが条件付き確率と呼ばれるもので、条件となる事象を縦棒 \(|\) の後に書き、その条件下で注目している事象を縦棒 \(|\) の前に書きます。同様に、「客が傘を持っていたという条件の下で、そのとき雨が降っていた確率」は、上の表から \(6 / 7\) なので、以下が成り立ちます。
これらの 2 つの確率が、それぞれ \(p(Y = 0, X = 1) = 1 / 16\) , \(p(Y = 1, X = 1) = 6 / 16\) という同時確率とは異なっていることを、上の同時分布表と見比べて確認してみましょう。 「客が傘を持っていてかつ外で雨が降っている」という同時確率は \(6 / 16\) となっていますが、「客が傘を持っているという条件の下で外で雨が降っている」という条件付き確率は \(6 / 7\) でした。 前者は「客が傘を持っておらず外で雨が降っていた」「客が傘を持っておらず外で雨が降っていなかった」「客が傘を持っていたが外で雨が降っていなかった」を含むあり得る全ての事象を考えた上で、その中で対象としている事象「客が傘を持っていて外で雨が降っている」が起こる確率を意味しています。一方で、後者の条件付き確率は、今条件となっている事象「客が傘を持っている」が成り立っている事象だけをまず対象とし、その中で着目している事象「外で雨が降っている」が起こる確率を考えます。それぞれの確率の値を計算する際の分母が異なっていることに注目してください。
また、上記の 2 つの条件付き確率を足すと、 \(1\) になります。「ある条件下で」という制約された世界で、対象とする確率変数がとり得る値全ての確率を並べて一覧したものは条件付き分布(conditional distribution)と呼ばれ、それらの確率を全て足すと必ず \(1\) になります。上の例では、以下の計算で確かめられます。
ここで、確率変数 \(X\) がとりうる実際の値のうちいずれかを表す文字として \(x\) を、確率変数 \(Y\) がとりうる実際の値のうちいずれかを表す文字として \(y\) を用いると、一般的に、条件付き確率は以下のように定義されます。
このとき、条件付き分布が満たす条件は以下のように表せます。
ここで、 \(\sum_x P(Y = y | X = x)\) は必ずしも1にならないということに注意してください。
では、上の条件付き確率の定義を用いて、同時確率と周辺確率から条件付き確率を、再度計算してみましょう。
確かに、上で別の方法で求めた条件付き確率と一致しました。
さて、上で触れた、同時確率と条件付き確率の関係について再度考えてみましょう。前述の「条件付き確率の定義」の式を変形すると、以下のようになります。以降では、簡単のために、確率変数の記述を省き、 \(p(X = x)\) を \(p(x)\) と表記します。確率変数 \(X\) によって \(x\) という値に対応付けられている事象が生じる確率、という意味です。同様に、 \(p(Y = y)\) を \(p(y)\) と表記します。
同時確率は、条件付き確率に、その条件となっている事象が生じる確率(周辺確率)を掛け合わせることで得られることが分かります。
今回の例では、「雨が降っているかどうか」によって「客が傘を持っていたかどうか」は影響を受けるため、2つの確率変数 \(Y, X\) は従属 (dependent)、と言います。一方、例えば「客が来たとき雨が降っていたかどうか」と「私が今お腹が空いているかどうか」が全く関係していないとします。後者について、お腹が空いているという事象を \(1\) に、お腹が空いていないという事象を \(0\) に対応付ける確率変数 \(Z\) を導入すると、\(Y\) と \(Z\) が今独立 (independent)であるという状況です。このとき、\(Z\) の実現値を \(z\) として、条件付き確率 \(p(y | z)\) は、\(Y\) がどうなるかが \(Z\) がどうなるかに全く関係がないことから、 \(p(y)\) と等しくなります。条件付けたとしても、条件付けなかったとしても、結果が変わらないためです。これを用いると、 \(y\) と \(z\) の同時確率は以下のように変形できます。
\(Y\) と \(Z\) が独立であることから、 \(p(y | z) = p(y)\) となることを用いました。この式から、2つの確率変数が独立であるとき、同時確率はそれぞれの周辺確率の積で書けるということが言えます。
ベイズの定理¶
前節で説明した条件付き確率は、ある前提が成り立っている状況下で着目する事象が生じる確率を記述するためのものでした。これは、「ある」原因」が生じたという条件の下で、ある」結果」が生じる確率」を考えていると捉えることができます。では、逆に「ある」結果」が観測されたというとき、ある事象が」原因」である確率」を考えるにはどうしたら良いでしょうか。今、原因となり得る事象が確率変数 \(X\) で表され、結果となり得る事象が確率変数 \(Y\) で表されるとします。このとき、原因として実際に \(x\) が観測されたもとで結果が \(y\) となる確率が条件付き確率
で表されました。前節の定義から、これに原因 \(x\) がそもそも発生する確率 \(p(X = x)\) を掛け合わせると、同時確率 \(p(Y = y, X = x)\) になります。すなわち、
です。では、結果が \(y\) であったという観測の下で、原因が \(x\) である確率はどのように表されるでしょうか。これは上の「条件の事象」と「着目する事象」を入れ替えた条件付き確率として、
と書くことができます。 \(y\) という結果が観測されたもとで、原因が \(x\) であった確率という意味です。これに結果 \(y\) がそもそも発生する確率 \(p(Y = y)\) をかけ合わせると、条件付き確率の定義から
が導かれます。ここで、式(1)と式(2)の右辺が同じになっていることに着目します。すると、式(1)と式(2)の左辺同士を等号で結ぶことができ、
が成り立つことが分かります。この式を変形して、求めたい「結果 \(y\) が生じたという条件の下で原因が \(x\) である確率」を左辺に残すと、
が導かれます。これをベイズの定理(Bayes』 theorem)と言います。これによって、ある結果が観測されたときに、ある事象が原因である確率を、
原因として考えている事象が(結果と関係なく)そもそも生じる確率( \(p(X = x)\) )
結果として観測した事象が(原因に関係なく)そもそも生じる確率( \(p(Y = y)\) )
考えている原因が実際に生じたという下で観測された結果が生じる確率( \(p(Y = y | X = x)\) )
の3つから、求めることができます。ベイズの定理に登場する左辺の条件付き確率と右辺の分子にある周辺確率には、特別な呼び方があります。まず右辺の分子にある周辺確率(上式では \(p(X = x)\) )は、「結果」が観測する前(事前)に、原因 \(x\) がそもそも生じる確率を表すので、事前確率(prior probability)と呼ばれます。一方、左辺の条件付き確率(上式では \(p(X = x | Y = y)\) )は、ある「結果 \(y\)」が観測されたという条件の下で(事後に)、原因 \(x\) が生じていたという確率を表すので、事後確率(posterior probability)と呼ばれます。
ベイズの定理の応用事例として、スパムメールフィルターがあります。まず、 \(N\) 個の着目する単語 \(w_i (i=1, \dots, N)\) を決めます(」sale」, 「buy」, 「free」, …など)。そして、メールにある単語 \(w_i\) が含まれるとき \(1\) となり、含まれないとき \(0\) となる確率変数を \(W_i\) とし、「メールにある単語 \(w_i\) が含まれる確率」を \(p(W_i = 1)\) とします。 次に、メールがスパムメールであるとき \(1\) となり、スパムメールでないとき \(0\) となる確率変数を \(Y\) とし、「スパムメールの存在確率」を \(p(Y = 1)\) とします。このとき、「あるメールがスパムメールであったという状況の下で単語 \(w_i\) が含まれていた」という確率は \(p(W_i = 1 | Y = 1)\) となります。すると、例えば \(w_i\) と \(w_j\) が両方含まれていた場合は、同時確率 \(p(W_i = 1, W_j = 1 | Y = 1)\) を考えることになりますが、各単語が独立に現れると仮定すると、これは \(p(W_i = 1 | Y = 1) p(W_j = 1 | Y = 1)\) と分解できます。ここで、世の中にある大量のメールを集めて、各単語がどのくらいの確率で現れるかを調べると、 \(p(W_i = 1) \ (i=1,\dots,N)\) が求まります。また、集めたメールからスパムメールだけを抜き出します。すると、メールがスパムメールである確率 \(p(Y = 1)\) が求まります。さらに、それらのスパムメール中に含まれる単語を調べ、どの単語がどういう確率で出現しているかを、着目している全単語について求めると、 \(p(W_i = 1 | Y = 1) \ (i=1, \dots, N)\) が全て求まります。これらを用いると、「あるメールに単語 \(w_i, w_j, w_k, \dots\) らが含まれているとき、そのメールがスパムメールである確率」を以下のように計算できます。
尤度と最尤推定¶
これまでの節では、「確率変数がとりうる様々な値に確率を対応させる」確率分布は、表の形で表されていました。ここで、確率変数 \(X\) が \(x\) という値をとる確率 \(p(X = x)\) を、表の代わりに、あるパラメータ \(\theta\) で特徴づけられた関数 \(f(x; \theta)\) によって表してみます。この関数は、「確率変数 \(X\) がとりうる様々な値 \(x\) に確率を対応させる」ので、 \(X\) の確率分布を表しています。このような関数は確率モデル(probabilistic model)とも呼ばれ、特にパラメータによって形状が決定される関数を用いる場合はパラメトリックモデル(parametric model)と呼ばれます。
このような確率モデルのパラメータをうまく決定することで、データの分布を表現できれば、未知のデータに対してもそれがどのくらいの確率で発生するのかといった予測が可能となったり、便利です。推定方法には様々なものがあり、どうやって推定するかは推定する人の自由ですが、本節では最も一般的な方法の一つである最尤推定を説明します。最尤推定は確率論から正当化できるという長所があります。
さて、確率モデルがどのくらい実際の観測データに即しているかを尤度(ゆうど)(likelihood)と言い、観測されたデータをモデルに入力し、その出力をかけ合わせたもので定義されます。
例えば、 \(N\) 個のデータ \(x_i \ (i=1,\dots,N)\) が独立に観測されたとき、この観測データの下での確率モデル \(f(x; \theta)\) の尤度は
と計算されます。与えられたデータから、「どのようなデータがどのくらいよく観測されるか」を表す確率分布を推定(注釈5)するために、予め用意した確率モデルのパラメータを、それらの観測データの下での尤度が最大になるように決定する方法を、最尤(さいゆう)推定(maximum likelihood estimation)と言います。
上式の \(\prod\) という記号は、 \(\sum\) の掛け算版で、全ての値を掛け合わせるという意味です。複数データに対する尤度は、 \(1\) より小さな値の積となるため、結果は非常に小さな数になり、コンピュータでこの計算を行う際にはアンダーフローという問題が発生しやすくなります。また尤度を最大化したい場合、積の形の式の最大化は難しいことが知られています。そこで尤度の対数をとった対数尤度(log likelihood)を考えます。 \(y = \log(x)\) は単調増加であるため、対数をとる前後で大小関係は変わりません。そのため対数尤度を最大にするときの \(\theta\) は、元の尤度も最大にします。
よって、この対数尤度を最大化するパラメータ \(\theta\) を求めることができれば、その値が観測データ \(x_i (i=1,\dots,N)\) の分布を最もよく表現する確率モデルのパラメータとなります。
例:コイントスのパラメータ推定¶
ここで、具体例として、コインの表・裏が出る確率を推定する問題を考えてみます。コインを投げて「表が出る」事象を \(1\) に、「裏が出る」事象を \(0\) に対応付ける確率変数を \(X\) とします。このとき、 \(p(X)\) をシンプルな確率モデル
で表現することにします(注釈6)。これは \(x = 1\) のとき、すなわちコインが表であるとき \(\theta\) をそのまま返し、 \(x = 0\) のとき、すなわちコインが裏であるとき \(1 - \theta\) を返すような関数となっています。ただし、 \(0 \leq \theta \leq 1\) を満たすこととします。今、コインを \(10\) 回投げ、以下の観測結果が得られたとします。
\(\ \) |
1回目 |
2回目 |
3回目 |
4回目 |
5回目 |
6回目 |
7回目 |
8回目 |
9回目 |
10回目 |
|---|---|---|---|---|---|---|---|---|---|---|
X |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
これらの観測データの下での確率モデルの尤度は
です。対数尤度は、
となります。これが最大となるときの \(\theta\) は、この式を \(\theta\) で微分した式を \(0\) とおいて解析的に解けばよく、
と決定します。これが最尤推定です。
事後確率最大化推定(MAP推定)¶
前節で解説した最尤推定は、多くの場合で有用ですが、求めるパラメータに何らかの事前知識があっても、それを活かすことができません。そのため、サンプルサイズが小さい場合に、実際にはほとんどあり得ない結果が求まることがあります。具体例を見てみましょう。
再び、コインの表・裏が出る確率を推定する例を考えます。コインを \(5\) 回投げたところ、たまたま \({\bf 5}\) 回とも表が出たとします。この場合、前節と同じ確率モデルを用いて尤度を計算し、最尤推定でモデルのパラメータを決定すると、 \(0 \leq \theta \leq 1\) を満たしながら、今回の観測データの下での尤度 \(\theta^5\) を最大にする \(\theta\) は \(1\) となります。これは「表が出る確率が \(1\) 」すなわち「裏面が出る確率は \(0\)」という推定結果が得られてしまったことを意味します。もし「裏が出る確率も \(0\) よりは大きいだろう」という事前知識を持っておりそれを活用できれば、今回のような場合でもより良い推定ができそうです。
事前知識も考慮しながら、観測データに基づいて確率モデルのパラメータを推定する方法には、事後確率最大化(maximum a posteriori, 以降 MAP)推定があります。MAP 推定でも、対象のデータの確率分布を表す確率モデルのパラメータを、データを利用して決定しますが、データだけでなくパラメータも確率変数だと考える点が最尤推定とは異なっています。パラメータを確率変数 \(\Theta\) とすると、このパラメータがどのような値をとるかを表す分布 \(p(\Theta)\) が導入できます。これを事前分布(prior distribution)と呼び、ここに「求めたいパラメータに対する事前知識」を反映させることができます。ここで、 \(\Theta = \theta\) となる確率 \(p(\Theta = \theta)\)(以降は \(p(\theta)\) と略記)をデータの確率モデル \(f(x; \theta)\) とは別の確率モデル \(g(\theta; \beta)\) で表せば、 \(\beta\) を人為的に与えるか、なんらかの方法で決定しておくことで、「どのような \(\theta\) が起こりやすいか」という事前知識を表現することができます。
MAP 推定では、観測データ \(x_i \ (i=1,\dots,N)\) が観測されたという条件の下で最も確率が大きくなる \(\theta\) を求めます。すなわち、 \(p(\theta | x_1, \dots, x_N)\) を最大とする \(\theta\) を求めます。これは「 \(x_i \ (i=1,\dots,N)\) が観測された」という結果のもとで「データの確率分布を表すモデルのパラメータが \(\theta\) であったことが原因である」確率を意味するので、事後確率です。ベイズの定理から、事後確率は
と書けました。右辺に着目してください。分子にある \(p(x_1,\dots,x_N | \theta)\) を、確率モデル \(f(x; \theta)\) を用いて \(\prod_{i=1}^N f(x_i; \theta)\) と表すと、これは観測データ \(x_i \ (i=1,\dots,N)\) の下での確率モデル \(f(x; \theta)\) の尤度です。また、その右の \(p(\theta)\) は、パラメータが \(\theta\) という値になる事前確率でした。これが \(g(\theta; \beta)\) という確率モデルで表されるとします。
今、事後確率を最大にするパラメータ \(\theta\) を求めるために、右辺を最大化する \(\theta\) を考えます。このとき、パラメータと無関係に決まる \(p(x_1,\dots,x_N)\) を無視し
だけに注目してこれを最大化するようにパラメータ \(\theta\) を決定すると、その \(\theta\) は求めたい左辺の事後確率を最大にする \(\theta\) に一致します。上式は、尤度と事前分布の積になっています。このことから、事後分布は尤度と事前分布の積に比例するということが分かります。
例:コイントスでのパラメータ推定¶
前節の最尤推定で用いたコイントスの例を再び考えます。 今度は MAP 推定を用いてパラメータを推定してみましょう。用いるデータは先程と同様の \(10\) 回のコイントス結果です。 また、確率モデル \(f(x; \theta)\) も同様に最尤推定の場合と同様のものを用います。 MAP 推定では確率モデル \(f(x;\theta)\) の他に、事前分布 \(p(\theta)\) を設計する必要があります。 \(p(\theta)\) の決め方は推定を行う人がどのような事前知識(もしくは信念)を持っているかによって自由に選択することができますが、ここでは事前分布を
と設定します(注釈7)。 グラフを書くと \(p(\theta)\) は \(\theta = 1/3\) で最大値をとることがわかります。これは「コイントスが行われる前には、実験者は \(\theta=1/3\) が最もあり得る可能性である」すなわち、「このコインは表よりも裏の方が出やすい」と信じている(事前知識を持っている)と解釈することができます。
事後分布は \(\theta\) の関数として \(p(x_1, \ldots, x_N | \theta) p(\theta)\) に比例するのでした。 これを具体的に計算すると
となります。これを \(\theta\) の関数として最大化します。 最尤推定の時と同様に、この値そのものではなく、対数を取った値を最大とする \(\theta\) を求めます。
ここで, \(const.\) は \(\theta\) に依存しない定数(具体的には \(\log 12\) )で、値を最大にする \(\theta\) を決定するのに影響を及ぼしません。 これを \(\theta\) で微分したものが \(0\) に等しいという方程式を立てると、
と解くことができます.これが MAP 推定で得られた推定値です。
最尤推定で得られた推定値は \(\theta = 1/2\) だったので、MAP 推定は最尤推定よりも低めに \(\theta\) を推定していることがわかります。 これは事前分布 \(p(\theta)\) により \(\theta\) は \(1/2\) より小さい値が出やすいという事前知識を入れていたことを反映しています。逆に事前分布で大きい \(\theta\) が出やすいという事前知識を入れれば、MAP 推定の値を最尤推定よりも大きくすることができます。
この例からも分かる通り、MAP 推定は事前分布の設定により得られる推定値が変化します。 この事は、MAP 推定の方が事前知識により柔軟なモデリングができる半面、誤った事前知識に基づいて事前分布を設計すると、推定値が実際のデータと乖離する可能性を持つことを意味します。
統計量¶
本節では、いくつかよく用いられる統計量を説明します。統計量とは、観測されたデータの特徴を要約する数値のことを指します。代表的な統計量として平均、分散、標準偏差を紹介します。
平均¶
平均 (mean) は、観測された数値を合計し、その数値の個数で割ったもののことを言います。たとえば、300 円、400 円、500 円の平均は、
です。一般に、 \(N\) 個のデータ \(x_i \ (i=1,\dots,N)\) が観測されたとき、その平均は
と定義されます。 平均を表す記号として、 \(\bar{x}\) や \(\mu\) がよく用いられます。 データの分布において、平均はその重心に相当する値です。
分散¶
次に、分散 (variance) を紹介します。分散はよく \(\sigma^2\) と表され、
と定義されます。各データ点 \(x_i \ (i=1,\dots,N)\) の値から、それらの平均 \(\bar{x}\) を引き二乗した値( \((x_i - \bar{x})^2 \ (i=1,\dots,N)\) )の平均を計算しています。これは、「データが自らの平均より平均的にどのくらいばらついているか」を表します。平均が同じデータでも、全てのデータが平均付近にある場合は分散は小さく、平均よりも極めて大きなデータ点や小さなデータ点が多数ある場合、分散は大きくなります。分散にはもう一種類あります。以下のようなものです。
始めに登場した \(\sigma^2\) の定義では \(\frac{1}{N}\) となっていた部分が \(\frac{1}{N - 1}\) に変わっています。 前者は標本分散 (sample variance) といい、後者は不偏分散 (unbiased variance) といいます。 これらの式の導出は他の文献に譲るとして、ここではその使い分けについて説明します。
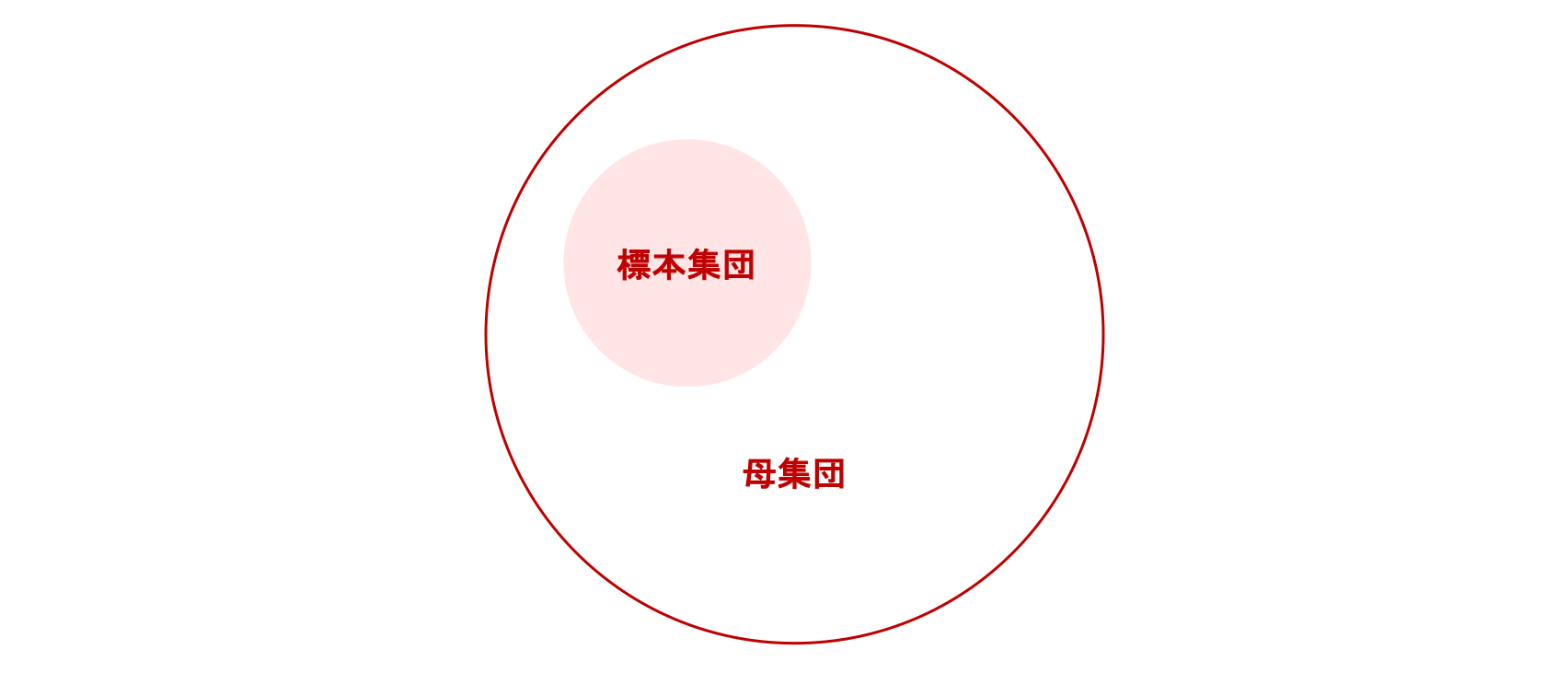
例えば、全国の小学生の身長と体重の分散を調べたいとします。このとき、全国の小学生を一人の抜け漏れもなく調べたなら、集まったデータは母集団 (population) と呼ばれます。 一方、各都道府県の小学生を100人ずつ調べた場合、そのデータは標本集団 (sample population) と言います。 すなわち、母集団とは解析を行いたいデータ全ての集合を指し、標本集団とは母集団から抽出された一部のデータの集合を指します。一般に、標本集団のデータ数が少ないとき、標本分散は母集団の分散よりも小さくなることが知られています。不偏分散は、その差を補正することで、母集団の分散をより正確に推定するために用います。不偏分散は抽出するデータの数(\(N\))を増やせば、いずれ母集団の分散に一致します。また、\(N\) が大きいと標本分散と不偏分散はほぼ一致するので、たくさんのデータ数をとることができる状況では、両者に大きな違いが生じないことも多々あります。
分散を利用すると、データのばらつきを定量評価することができるようになります。例えば、同じ現象を複数回観測する実験を行った際、結果のばらつきが大きければ、その観測方法には問題がある可能性があります。もしくは、同じだと思っていた現象は、実は観測のたびに異なる現象であった可能性があります。このように、多数の試行の結果がある値に集まっていることが望ましいような状況において、ばらつきの度合いを定量し評価することは重要です。
標準偏差¶
次に標準偏差 (standard deviation) を紹介します。 分散はデータの平均からの差の二乗の平均でした。そのため単位は元の単位を二乗したものになります。例えばデータの単位が \({\rm kg}\) であれば、分散の単位は \({\rm kg}^2\) になります。そこで、分散 \(\sigma^2\) の平方根 \(\sigma\) を計算することで、データと単位が等しくなり、解釈が容易になります。この \(\sigma\) を標準偏差と呼びます。
練習問題で具体的な計算手順の確認を行いましょう。以下の①と②のデータに対して、平均、分散、標準偏差を求めてください。ただし、今回は標本分散を使用することとします。

①の解答は以下の通りです。
②の解答は以下の通りです。
これより、②のケースの方が分散が大きく、データのばらつきが大きいことがわかります。
相関係数¶
最後に相関係数 (correlation coefficient) を紹介します。
2 種類のデータが得られている状況では、両者の関係性の解析がしばしば重要となります。 相関係数は両者の関連の度合いを定量的に測るのに用います。
2 種類のデータ点がスカラー値で \(N\) 個ずつある状況を考えます。それぞれを \(x_n, y_n \ (n=1,\dots,N)\) とした場合、相関係数の中でも良く用いられるピアソンの相関係数は以下のように定義されます。
上式のように相関係数を表す記号は \(r\) を用いるのが一般的です。 相関係数 \(r\) は常に \(-1 \leq r \leq 1\) になり、相関が認められるとき、 \(r\)の値が正の場合は正の相関があるといい、逆に負の値のときは負の相関があるといいます。
2 種類のデータ間の相関が強いほど \(r\) の絶対値は大きくなります。 しかし、「\(r\) がいくつ以上ならば相関があると思って問題ない」という閾値はタスクごとに異なり、例えば \(r=0.2\) から相関ありと判断してよいかは一概には言えません。本資料では説明を省略しますが、無相関検定などの手法を利用することで客観的な判断を行うことができます。
注釈 5
以降、このことを「データの分布を推定する」と言うことがあります。また、観測されたデータのみから各データの発生確率(頻度とも捉えられる)を求めたものは経験分布(empirical distribution)とも呼ばれ、本節で説明しているのは正確にはこの経験分布を確率モデルで近似する方法です。
注釈 7
先頭の \(12\) は \(p(\theta)\) \(0\) から \(1\) まで積分した値が \(1\) となるように決めています。これにより、\(p(\theta)\) が \(0 \leq \theta \leq 1\) の上の確率分布となります。